
TextEdu — описание программного алгоритма решения задачи по обработке учебных текстов.
Для приведения текстов в соответствие с требованиями используется текстовый редактор Microsoft Word и его инструмент (команда) «Заменить». В версии Word 2019 она запускается кнопкой «Заменить», расположенной на панели инструментов «Редактирование» вкладки «Главная»:
Рисунок 1. Кнопка «Заменить»
Также команда может запускаться нажатием горячих клавиш ctrl+h. В других версиях текстового редактора запуск команды может осуществляться по-иному, однако она, как правило, будет находиться на главной вкладке.
Перед началом работы с текстом рекомендуется выделить весь текст, воспользовавшись комбинацией ctrl+a (либо кнопка «Выделить все» на панели инструментов):

Рисунок 2. Кнопка «Выделить все»
После чего, не снимая выделения выровнять текст по обоим краям страницы (по ширине), воспользовавшись комбинацией ctrl+j, либо кнопкой «Выровнять по ширине» на панели инструментов.
Рисунок 3. Кнопка «Выровнять по ширине»
Текст приобретет выровненный по двум краям вид.

Рисунок 4. Результат выполнения команды «Выровнять по ширине»
1. Удаление номеров страниц
Номера страниц подлежат удалению. На рисунке интересующие нас символы обозначены красным цветом.

Рисунок 5. Пример номера страницы для удаления
Мы видим, что после автоматического распознавания, номера страниц представляют из себя цифру, которая может состоять как из одного, так и из нескольких символов. До этого набора располагается знак абзаца (окончание предыдущей строки, обозначаемое при просмотре специальным символом «¶») и после номера страницы следует так называемый «Разрыв страницы» (управляющий символ Word, принудительно перемещающий текст на следующую страницу даже если на текущей еще присутствует свободное место).
Для удаления номеров страниц необходимо запустить выполнение команды «Заменить». Для этого кликаем на одноименную кнопку на панели инструментов и переходим к заполнению параметров команды в появившемся всплывающем окне.
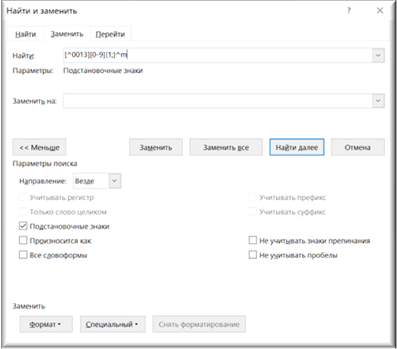
Рисунок 6. Всплывающее окно «Найти и заменить»
Значение поля «Найти» должно явно описывать те символы, которые подлежат замене. Для этого используется специальный синтаксис, когда символы могут быть записаны «как есть» (например, «абв» именно как «абв»), так и с помощью «специальных символов»/«подстановочных знаков» (например, знак табуляции – «^t»).
Удобнее всего анализировать работу команды «Заменить» на конкретных примерах. Возвращаясь к поставленной задаче, можно сделать вывод, что для ее выполнения, в поле «Найти» необходимо ввести:
[^0013][0-9]{1;}^m
Разберем состав этой команды:
Конструкция [^0013] обозначает символ абзаца.
Набор [0-9] означает, что команде необходимо будет найти любую цифру от 0 до 9 включительно.
{1;} – данный параметр указывает на то, что символ обозначенный левее (в нашем случае цифра) может быть как единственным (например 1, 2, 7, 0 и т.п.), так и состоящим из нескольких последовательных цифр (22, 45, 178 и т.п.). Следует отметить, что введение параметра {1} без добавления знака «;» внутри фигурных скобок приведет в данном случае к поиску числа, состоящего только из одной цифры. С использованием знака «;» будут найдены значения, состоящие не менее чем из одной цифры, но, возможно более чем из одной (как 1, 2, 3, так и 12, 123, 1234 и т.д.). В случае если мы введем {2}, то это приведет к поиску значений из двух цифр (22, 15, 98, но не 1, 5, а также не 123, 445, 1919 и т.д.).
Последний элемент в поле «Найти» является подстановочным знаком «^m», обозначающим принудительный разрыв страницы.
 |
Следует обратить внимание, что команда будет искать только те значения, которые соответствуют всем заданным условиям, то есть если, например, в наборе символов будет отсутствовать разрыв страницы, то команда не будет обрабатывать данную строку. |
Следующим важным этапом является заполнение поля «Заменить на». В нем указывается на что конкретно требуется заменить набор символов, обозначенный полем «Найти». Поскольку в данном случае требуется полностью удалить все символы, указанные в поле «Найти», поле «Заменить на» следует оставить пустым.
|
Обратите внимание на то, что галочка «Подстановочные знаки» должна быть включена. Выполнение команды «Заменить на» происходит по-разному, в зависимости от включения, либо отключения данного параметра. Случаи, когда данный параметр подлежит выключению, будут специально оговорены. |
Обратите внимание, что направление поиска всегда должно иметь значение «Везде», а не «Вперед» или «Назад».

Рисунок 7. Указание на направление поиска
После нажатия на кнопку «Заменить», либо «Заменить все» наш абзац приобрел следующий вид.

Рисунок 8. Результат удаления страниц по команде «Заменить»
Как видно из рисунка, номер страницы, вместе с символом «Разрыв страницы» удален и текст следующего абзаца теперь располагается непосредственно за обработанной командой строчкой. Таким образом поставленная задача – выполнена.
2. Удаление сносок
Удаление сносок представляет из себя двухуровневую задачу, поскольку их символьная структура легко маскируется под обычный текст. В этой связи сноски подлежат первостепенному удалению.

Отличительной чертой сносок является то, что цифра, обозначающая порядковый номер сноски, пишется в верхнем регистре (например, 1, 3, 5 и т.п.). Кроме того, таким номерам всегда предшествует знак абзаца. Это позволяет с достаточной долей вероятности составить правильную поисковую строку для их обнаружения и удаления.
Однако особенности работы всплывающего окна «Найти и заменить» не позволяют одновременно искать символы в верхнем регистре и обычные, поэтому задача разбивается на два этапа.
На первом этапе все цифры документа, находящиеся в верхнем регистре, заменяются на уникальный набор символов, который точно больше нигде не встречается в тексте, а также не содержит подстановочных знаков (например, «RRR»).
Для осуществления данной задачи запускаем команду «Заменить». В поле «Найти» прописываем [0-9]{1;} (любая цифра), после чего жмем клавишу «Больше» (если окно не развернуто полностью):

Рисунок 9. Окно «Найти и заменить». Частично свернуто
Далее жмем кнопку «Формат» и во всплывающем меню «Шрифт»:

Рисунок 10. Выбор параметров шрифта для поиска
Далее в открывшемся окне «Найти шрифт» делаем активным параметр «Надстрочный» и жмем на «ОК».

Рисунок 11. Выбор параметров шрифта для поиска
Таким образом команда будет искать только цифры, расположенные в верхнем регистре.
В значении поля «Заменить на» указываем «RRR» и выполнить замену.
Далее, нужно обратить внимание, что Word не может одновременно вставлять новые абзацы и тут же учитывать их при обработке следующей строки. Это вызывает пропуск обработки сносок, идущих сразу друг за другом (возможно баг Word?). Для решения этой проблемы выполняется еще одна команда – впереди уже имеющихся символов абзаца и «RRR» добавляется второй знак абзаца, который пропадет на последующем этапе обработки:
Поле «Найти»: [^0013]RRR
Поле заменить на: ^p^pRRR
Не забудьте нажать на кнопку «Снять форматирование», чтобы отметка «Надстрочные» отсутствовала под полем «Найти», иначе последующие шаги алгоритма не будут работать.
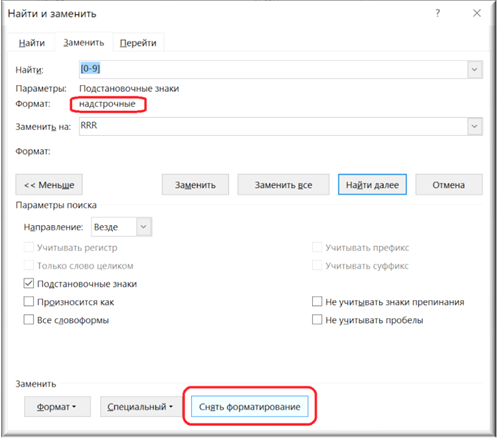
Рисунок 12. Очистка формата поиска
После выполнения команды сноски будут выглядеть следующим образом:

Рисунок 13. Порядковые номера сносок заменены символами «RRR», добавлен абзац
На этом первый этап преобразования завершен.
Для реализации второго этапа, в поле «Найти» вводим:
[^0013]RRR*.[^0013]
Значение поля «Заменить на» оставляем пустым.
Результат работы команды удалит из документа все сноски.

Рисунок 14. Результат удаления сносок
Не забудьте удалить оставшиеся символы RRR в тексте документа:
В поле «Найти»: RRR
В поле «Заменить на»: Оставить пустым
3. Удаление символов разрыва строк
Автоматизированная обработка текста оставляет после себя множество артефактов, которые необходимо удалять.
Одним из примеров является символ разрыва строк.

Рисунок 15. Пример символа разрыва строки
Существует два варианта удаления указанного символа. В том случае, если данному символу предшествует знак переноса «-», разделяющий слово на несколько частей, то удаление происходит задачей следующих параметров команды «Заменить»:
!!!Значение параметра «Подстановочные символы»: Отключено
Поле «Найти»: -^l
Поле «Заменить на»: оставить пустым.
В результате выполнения команды все слова с переносами будут восстановлены неразрывными и не содержащими как символа разрыва строки, так и символа переноса.

Рисунок 16. Пример удаления символов переноса и разрыва строки
Далее необходимо удалить все оставшиеся символы разрыва строки.
|
Следует обратить внимание, что при последовательном выполнении команд с одними и теми же переменными, одна из которых является более узкоспециализированной, обработку необходимо начинать именно с такой узкоспециализированной команды. В противном случае это может привести к появлению артефактов, которые не смогут быть компенсированы последующей работой алгоритмов. Например, в данном случае сначала выполняется команда удаления разрыва строки с переносом (как частный случай), поскольку помимо символа разрыва строки она убирает и сам символ переноса, и только после этого выполняется команда на удаление всех оставшихся разрывов строк (в условиях когда все имевшиеся символы переноса слова уже удалены). Если сделать в обратном порядке, то мы получим такие слова как «специализи-ровались» и отличить их от сложносоставного термина с дефисом будет весьма проблематично. |
Для удаления оставшихся символов разрыва строки воспользуемся следующими параметрами команды заменить:
!!!Значение параметра «Подстановочные символы»: Отключено
Поле «Найти»: ^l
Поле «Заменить на»: символ пробела.
Как видно из примера, содержание поля «Найти» отличается от предыдущего только отсутствием символа переноса «-» в начале поля.
В результате действия команды, все лишние символы переноса строки удалены.

Рисунок 17. Результат удаления символов разрыва строки
4. Удаление символов переноса слов
Не все символы переноса слов («-») могут быть удалены предыдущей операцией. Оставшиеся после ее выполнения символы переноса слов («-») также подлежат удалению. В ряде случае встречается ситуация, когда символ переноса используется вместо дефиса в сложносоставных понятиях. Такие символы должны остаться в тексте. Анализ показывает, что следом за знаком переноса, подлежащим удалению, всегда находится символ абзаца (может еще находиться символ разрыва строки или разрыва страницы, но они уже должны были быть удалены на предыдущих этапах работы алгоритма). Кроме этого, после символа абзаца идет прописная буква, являющаяся частью продолжения разорванного слова.

Рисунок 18. Пример наличия переноса слова
Для удаления таких символов переноса используются следующие параметры команды «Заменить» (не забудьте включить опцию «Подстановочные знаки»):
Поле «Найти»: ([а-я])-[^0013]([а-я])
Поле «Заменить на»: \1\2
Результатом выполнения команды будет:

Рисунок 19. Результат удаления символов абзаца и переноса слов
Помимо этого необходимо выполнить ту же команду без знака «-», потому как бывает, что перенос строки есть, но без этого символа:
Поле «Найти»: ([а-я])[^0013]([а-я])
Поле «Заменить на»: \1\2
Таким образом, указанная часть алгоритма успешно выполнена.
5. Преобразование в простой текст
Последующие этапы работы алгоритма потребуют перевести текст в вид с отсутствующим форматированием (без выделения шрифта полужирным, цвета и прочих параметров).
Для этого используется комбинация ctrl+a, либо команда «Выделить все», расположенная на панели «Редактирование».
Рисунок 20. Вызов команды «Выделить все»
Результатом выполнения команды будет выделение всего текста документа.
Далее требуется переместить весь текст в буфер обмена. Для этого необходимо воспользоваться командой «Вырезать» на панели инструментов «Буфер обмена» или воспользоваться комбинацией ctrl+x.
Рисунок 21. Команда «Вырезать»
Необходимо привести в обычный вид состояние полей документа. Для этого необходимо воспользоваться командой «Поля» на вкладке «Макет», где выбрать значение «Обычные».
Рисунок 22. Выбор значения полей документа
Далее можно возвращать текст назад на страницы. Для этого воспользуемся командой «Вставить»-«Сохранить только текст», расположенной на панели инструментов «Буфер обмена».
Рисунок 23. Команда «Сохранить только текст»
Результатом выполнения команды будет очистка текста от форматирования и его расположения на листах со стандартными значениями полей.

Рисунок 24. Текст после выполнения команды «Сохранить только текст»
Далее необходимо выровнять текст по ширине. Для этого необходимо предварительно повторно выделить весь текст (ctrl+a) и воспользоваться командой «Выровнять по ширине» на панели инструментов «Абзац».
Рисунок 25. Команда «Выровнять по ширине»
Результатом выполнения команды будет равномерное распределение текста по всей ширине листа.
Помимо этого, всему тексту необходимо назначить шрифт «Times New Roman» и установить 12 размер. Для этого необходимо выбрать шрифт и размер из соответствующих полей панели инструментов «Шрифт».

Рисунок 26. Выбор шрифта и его размера
Результатом выполнения указанных команд будет текст с соответствующим шрифтом и размером.

Рисунок 27. Результат выполнения команд форматирования текста
На этом процедура преобразования текста для последующей обработки завершена.
6. Обозначение разделов, глав, параграфов
Для корректной работы алгоритма на разных этапах, необходимо четко обозначить первый символ каждого раздела, главы и параграфа.
Как правило, указанные блоки имеют следующий вид:

Рисунок 28. Примеры раздела, главы и параграфа
Для однозначного обозначения данных блоков используется какой-либо набор символов, который гарантированно не встречается в тексте и при этом не содержит специальных символов/знаков подстановки. Сейчас будет использоваться значение «RRR». При этом, следует захватить и предыдущий символ абзаца во избежание ложного срабатывания команды при наличии схожих слов в середине текста (например, «Глава» может быть блоком текста или «Главой администрации», что совершенно разные вещи).

Рисунок 29. Определение параграфа, включая символы абзаца
|
Обратите внимание, что до начала обработки разделов, глав, параграфов если с их наименования начинается весь документ, то перед ним нужно поставить знак абзаца (самым первым символом документа), иначе первое название не будет обработано (см. рисунок ниже). |

Рисунок 30. Необходимо вставить абзац в самом начале документа
Итак, для обработки интересующих нас блоков, значения команды «Заменить» будут иметь следующий вид:
Для раздела:
Значение поля «Найти»: [^0013]Раздел
Значение поля «Заменить на»: ^pRRRРаздел
Для главы:
Значение поля «Найти»: [^0013]Глава
Значение поля «Заменить на»: ^pRRRГлава
Для параграфа:
Значение поля «Найти»: [^0013]([0-9]{1;}.[0-9]{1;}. )
Значение поля «Заменить на»: ^pRRR\1
Значения поля «Найти» для параграфа выглядит несколько сложным, но на самом деле речь идет лишь о нахождении нескольких последовательных цифр, разделенных знаком точки «.» (например «1.1. », «12.5 «, «55.4 ») которые записаны с новой строки (именно для этого первым делом идет [^0013]) и заканчиваются знаком пробела.
После выполнения команд, строки приобретают следующий вид:

Рисунок 31. Результат обработки текста
Таким образом, достигнута возможность однозначной идентификации разделов, глав и параграфов. В случае наличия в тексте иных составных частей, алгоритм подлежит корректировке, либо наименования подобных частей нужно привести в соответствие с заявленной данным руководством номенклатурой.
7. Удаление лишних абзацев в наименовании глав
Зачастую встречаются наименования глав, которые содержат в себе лишние символы абзацев.

Рисунок 32. Пример дефектного названия главы
Для разрешения указанной проблемы команда «Заменить» используется со следующими параметрами:
В поле «Найти»: (RRRГлава [0-9]{1;})[^0013]
В поле «Заменить на»: \1пробел
В результате отработки команды, указанная проблема успешно разрешается.
Рисунок 33. Пример исправления наименования главы
Можно переходить к следующему этапу обработки текста.
8. Удаление блока «Знать-уметь-владеть»
Блоки, в которых включены требования к знаниям, умениям, владениям подлежат удалению из текстов, поскольку они уже содержатся в иной документации.

Рисунок 34. Пример блока «Знать, уметь, владеть»
Большие объемы текста также можно удалить, воспользовавшись командой «Заменить». Для правильной работы необходимо лишь обосновано определить уникальные начало и конец удаляемых фрагментов. В данном случае мы видим, что все подобные блоки начинаются с нового абзаца словами «В результате изучения…» и данный блок оканчивается знаком точки (поскольку имеет место перечисление, то иные строки, внутри блока, оканчиваются точкой с запятой «;»).
Однако, следует обратить внимание, что для формирования наиболее универсального алгоритма нужно учесть, что в некоторых текстах (да и в одном тексте тоже), набор слов, идущих следом за «В результате изучения» и перед «должен:» может различаться. Конечно, можно ограничиться определением начала удаляемого участка только тремя словами, то есть непосредственно так: «[^0013]В результате изучения». Но в таком случае существует вероятность неправильной отработки команды, ведь так может начинаться и часть текста, которую как раз нужно оставлять.
Решается эта проблема введением дополнительных подстановочных знаков, предусматривающих не только начальные слова:
[^0013]В результате изучения*долж*:*.[^0013]
Заканчивать строчку необходимо символом абзаца ([^0013]), поскольку вероятность наличия знаков точки «.», кроме той, что находилась бы в конце блока, в конечном итоге сохраняется.
|
Следует отметить, что подстановочный знак «*» заменяет любое количество любых символов, включая буквы, цифры, табуляцию, абзацы, знаки препинания и иные. Это очень полезно в том случае, если строка для поиска постоянно меняется, но в ней все же остаются определенные наборы символов, позволяющие однозначно отличить искомый набор от любых других. |
Какие варианты может отработать подобное значение поля «Найти»?
Вот примеры:
- В результате изучения раздела студент должен: любой текст.
- В результате изучения главы студенты должны: любой текст.
- В результате изучения главы обучающиеся должны уверенно: любой текст.
И прочие подобные варианты. Все они будут правильно распознаны. Вместо красного текста может быть любой набор символов. Это не повлияет на правильность работы команды.
В том случае, если в данном тексте ключевые слова выглядят по-иному, значение поля «Найти» конечно же подлежит некоторой корректировке.
В поле «Заменить на» ставим знак абзаца: ^p.

Рисунок 35. Результат выполнения команды «Заменить» для блока «Знать, уметь, владеть»
Как видно, команда отработала правильно.
9. Удаление блока «Контрольные вопросы»
Блок «Контрольные вопросы» удаляется по аналогии с предыдущим.

Рисунок 36. Пример блока «Контрольные вопросы»
Блок подлежит удалению вплоть до следующего раздела, главы или параграфа, начало названия которых ранее было обозначено как «RRR». Для решения указанной задачи команда «Заменить» должна иметь следующие параметры:
Поле «Найти»: [^0013]Контрольные вопросы*RRR
Поле заменить: ^pRRR
Результатом выполнения команды будет полное удаление блока «Контрольные вопросы».
|
Внутри блока «Контрольные вопросы» могут встречаться подблоки (например, с тестами и иным). Это не должно являться препятствием и алгоритм сотрет все, что находится между словами «Контрольные вопросы» и началом следующего раздела, главы, параграфа. В том случае, если в вашем тексте словосочетание «Контрольные вопросы» именуется по-другому, то можно либо произвести корректировку записи в поле «Найти», либо провести замену иного названия на «Контрольные вопросы» соответственно. |
10. Создание структуры документа
Структура документов в Word формируется за счет обозначения участков текста стилями, такими как, например, «Заголовок 1», «Заголовок 2», «Заголовок 3». Таким образом формируется многоуровневая структура документа, с которой удобно работать.
Для формирования подобной структуры также может использоваться команда «Заменить».
Для оформления разделов значения полей будут следующими:
Поле «Найти»: RRR(Раздел*[^0013])
Поле заменить: \1 `Заголовок 1
Обратите внимание, что стиль (в нашем случае «Заголовок 1») задается во всплывающем меню «Найти и заменить» по нажатию кнопки «Формат» и далее в появившемся меню «Стиль…», и в новом окне «Найти стиль» — «Заголовок 1». Запускать данный выбор необходимо, когда курсор находится в поле «Заменить на», поскольку именно к результатам замены мы и должны применить стиль «Заголовок 1».
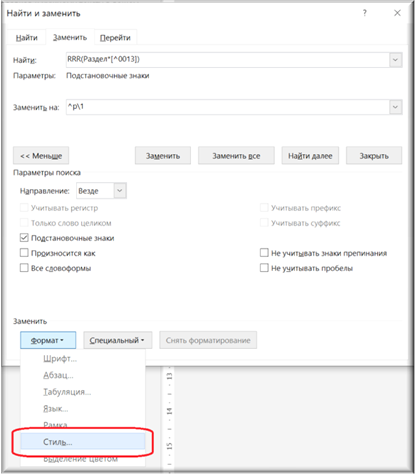
Рисунок 37. Меню «Стиль»
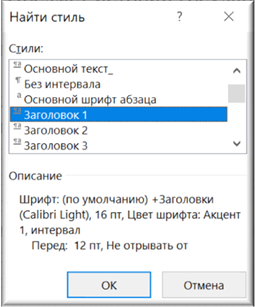
Рисунок 38. Всплывающее меню «Найти стиль»
Результатом выполнения команды будет являться удаление ранее поставленной отметки «RRR» перед названиями разделов, а также замена стиля наименований разделов. Структура разделов автоматически появится в области «Навигация» документа Word.
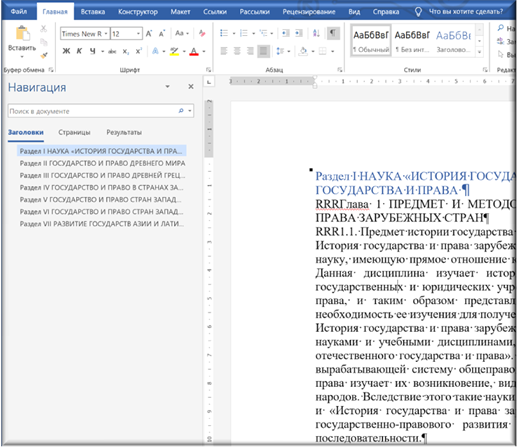
Рисунок 39. «Навигация» со сформированными разделами документа
Область «Навигация», помимо прочего, позволяет быстро перемещаться по документу, менять местами разделы, главы, параграфы.
Для формирования структуры в части глав, необходимо выполнить команду «Заменить» со следующими параметрами:
Поле «Найти»: RRR(Глава*[^0013])
Поле заменить: \1 `Заголовок 2
Обратите внимание, что стиль, используемый для глав, будет уже «Заголовок 2». Это необходимо проверить перед запуском команды.
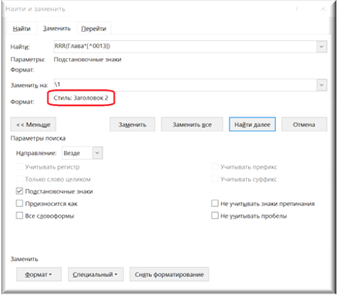
Рисунок 40. Стиль, который будет применен, после выполнения команды
Выполнение команды с такими параметрами приведет к следующей картине.
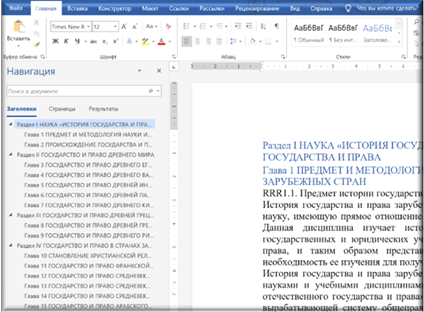
Рисунок 41. Область навигации пополнилась главами
Разрешение подобной обработки для параграфов выглядит аналогично.
Поле «Найти»: RRR([0-9]{1;}.[0-9]{1;}. *[^0013])
Поле заменить: \1 `Заголовок 3

Рисунок 42. Область навигации пополнилась главами
Не забывайте нажать на кнопку «Снять форматирование», чтобы избежать ошибок в работе алгоритма на последующих этапах.
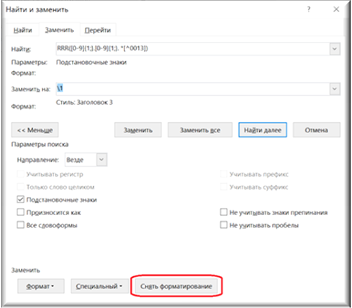
Рисунок 43. Удаление формата в полях команды «Заменить»
11. Удаление лишних записей в скобках
Некоторые записи в тексте, содержащиеся внутри круглых скобок («( )») подлежат удалению. К таким участкам относится весь текст с скобках, если он содержит любую арабскую или римскую цифры (например, тест (текст в скобке 12), или (текст XII в скобке)).
Задача имеет многошаговое решение.
Теория вопроса такова. При попытке поиска по шаблону (*[0-9]*) может возникнуть следующая ситуация: (какой-то текст, еще текст) обычный текст за скобками (еще один текст 123 и еще текст) и снова обычный текст. При таком подходе команда сначала найдет первую скобку и далее будет искать цифру даже несмотря на выход за пределы закрывающей скобки «)». Таким образом будут удалены все фрагменты в первых круглых скобках и вплоть до текста в последующих круглых скобках, содержащих цифры. Также будет необоснованно удален весь полезных текст между ними.
Решением указанной проблемы является предварительное ограничение областей поиска только текстом в скобках. Для этого необходимо как-то выделить этот текст, отграничив его от другого. Удобнее всего это делать с использованием параметра цвета шрифта.
|
Обратите внимание, что для поиска символов, которые сами по себе являются подстановочными знаками необходимо в поле «Найти» размещать перед ними знак «\», то есть при необходимости найти левую круглую скобку «(» запрос необходимо писать как «\(». |
Для выделения красным шрифтом всего текста, расположенного в круглых скобках, используется команда «Заменить» со следующими параметрами:
Поле заменить: \1 `Красный цвет
Красный цвет шрифта в поле «Заменить на» устанавливается при нажатии кнопок «Формат», и далее в выпадающем меню «Шрифт».
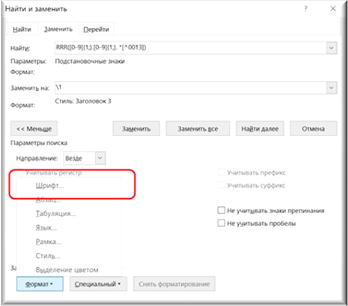
Рисунок 44. Выбор параметров шрифта
Цвет или иные параметры шрифта выбираются во всплывающем окне «Найти шрифт».
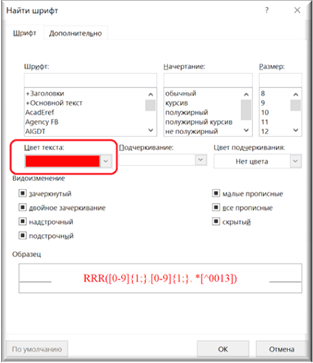
Рисунок 45. Выбор цвета шрифта
Результатом работы команды будет являться:

Рисунок 46. Выделение участков текста другим цветом
Теперь появляется возможность указать команде «Заменить», что обработку текста надо производить именно в пределах красного шрифта. Для удаления текста, обрамленного круглыми скобками, и содержащего любую арабскую цифру (несколько цифр) выполним команду «Заменить» со следующими параметрами:
Поле «Найти»: \(*([0-9])*\) `Красный шрифт
Поле заменить: пустое поле
Выполнение такой команды уберет весь текст, включая знаки скобок типа: «(любой текст или его отсутствие; любая цифра; любой текст или его отсутствие)».
Выполнение подобной операции для арабских цифр выполняется со следующими параметрами:
Поле «Найти»: \(*([XVIL])*\) `Красный шрифт
Поле заменить: пустое поле
По окончании указанных этапов необходимо вернуть цвет шрифта оставшихся записей в черный. Для этого выполняем команду «Заменить»:
Поле «Найти»: (\(*\))
Поле заменить: \1 `Цвет шрифта «Авто»

Данная часть обработки текста успешно выполнена.
12. Удаление лишних знаков абзаца
В результате обработки и по другим причинам в тексте могут образовываться лишние знаки абзацев. Под лишними знаками абзацев подразумевается два или более последовательно идущих друг за другом подобных знака.

Рисунок 47. Пример парного абзаца
Из всей группы необходимо оставить только один. Эта задача разрешается выполнением команды «Заменить» со следующими параметрами:
Поле «Найти»: [^0013][^0013]
Поле заменить: ^p

Рисунок 48. Удаление парных абзацев
13. Удаление двойных пробелов
Двойные пробелы удаляются из текста путем выполнения команды заменить со следующими параметрами:
Поле «Найти»: символ пробела{2;}
Поле заменить: символ пробела

Рисунок 49. Пример парного пробела
Таким образом из текста будут удалены все пробелы, следующие друг за другом два или более раза. Группы пробелов будут заменены одним.

Рисунок 50. Удаление парного пробела
14. Замена неправильных символов
Появление ошибочных символов является результатом автоматизированной обработки текста. Решается эта проблема заменой одних символов другими (нужными).
На текущий момент замене подлежат следующие сочетания.
Поле «Найти»: -.
Поле заменить: :
Поле «Найти»: ‘
Поле заменить: пустое поле
Таким образом, сочетание символов «-.» будет заменено на «:», а символ «’» будет удален.
15. Удаление пробелов перед знаками препинания
В ряде случаев в тексте образуются лишние пробелы перед знаками препинания (например, « ,», « ;» и т.п.). Они подлежат удалению. Для решения указанной задачи команда «Заменить» выполняется со следующими параметрами:
Поле «Найти»: символ пробела([.,:;\!\?])
Поле заменить: \1
Результатом выполнения команды будет удаление лишних пробелов.
16. Последовательность выполнения алгоритма
- Удаление номеров страниц
- Поле «Найти»: [0-9]{1;}^m
- Поле «Заменить на»: оставить пустым
- Удаление сносок
- Поле «Найти»: [0-9]{1;} `верхний регистр
- Поле «Заменить на»: RRR
- Поле «Найти»: [^0013]RRR
- Поле «Заменить на»: ^p^pRRR
- Поле «Найти»: [^0013]RRR*.[^0013]
- Поле «Заменить на»: оставить пустым
- Поле «Найти»: RRR
- Поле «Заменить на»: оставить пустым
- Удаление символов разрыва строк
- Поле «Найти»: -^l `Опция подстановочные знаки должна быть отключена
- Поле «Заменить на»: оставить пустым
- Поле «Найти»: ^l `Опция подстановочные знаки должна быть отключена
- Поле «Заменить на»: Пробел
- Удаление символов переноса строк
- Поле «Найти»: ([а-я])-[^0013]([а-я])
- Поле «Заменить на»: \1\2
- Поле «Найти»: ([а-я])[^0013]([а-я])
- Поле «Заменить на»: \1\2
- Преобразование в простой текст
- Обозначение разделов, глав, параграфов
- Поле «Найти»: [^0013]Раздел
- Поле «Заменить на»: ^pRRRРаздел
- Поле «Найти»: [^0013]Глава
- Поле «Заменить на»: ^pRRRГлава
- Поле «Найти»: [^0013]([0-9]{1;}.[0-9]{1;}. )
- Поле «Заменить на»: ^pRRR\1
- Удаление лишних абзацев в наименовании глав
- Поле «Найти»: (RRRГлава [0-9]{1;})[^0013]
- Поле «Заменить на»: \1пробел
- Удаление блока «Знать, уметь, владеть»
- Поле «Найти»: [^0013]В результате изучения*долж*:*.[^0013]
- Поле «Заменить на»: ^p
- Удаление блока «Контрольные вопросы»
- Поле «Найти»: [^0013]Контрольные вопросы*RRR
- Поле «Заменить на»: ^pRRR
- Создание структуры документа
- Поле «Найти»: RRR(Раздел*[^0013])
- Поле «Заменить на»: \1 `Заголовок 1
- Поле «Найти»: RRR(Глава*[^0013])
- Поле «Заменить на»: \1 `Заголовок 2
- Поле «Найти»: RRR([0-9]{1;}.[0-9]{1;}. *[^0013])
- Поле «Заменить на»: \1 `Заголовок 3
- Удаление лишних записей в скобках
- Поле «Найти»: (\(*\))
- Поле «Заменить на»: \1 `Красный цвет
- Поле «Найти»: \(*([0-9])*\) `Красный цвет
- Поле «Заменить на»: оставить пустым
- Поле «Найти»: \(*([XVIL])*\) `Красный цвет
- Поле «Заменить на»: оставить пустым
- Поле «Найти»: (\(*\))
- Поле «Заменить на»: \1 `цвет Авто
- Удаление лишних знаков абзаца
- Поле «Найти»: [^0013][^0013]
- Поле «Заменить на»: ^p
- Удаление двойных пробелов
- Поле «Найти»: пробел{2;}
- Поле «Заменить на»: пробел
- Замена неправильных символов
- Поле «Найти»: -.
- Поле «Заменить на»: :
- Поле «Найти»: ‘
- Поле «Заменить на»: оставить пустым
- Удаление пробелов перед знаками препинания
- Поле «Найти»: пробел([.,:;\!\?])
- Поле заменить: \1
- Рекомендуется выполнить пункт 4 еще раз.
- Создание макросов автоматической обработки
- На основании представленного алгоритма могут быть созданы макросы, обрабатывающие текст в том числе что называется одной кнопкой. Вместе с тем, результаты их работы должны проверяться вручную с особой тщательностью. Нами создан текст готового макроса, который может быть предоставлен дополнительно. Необходимо обладать начальными знаниями по работе с макросами, поскольку, в рядке случаев, в него потребуется вносить изменения.
- Последующая ручная проверка
- Все тексты, обработанные командой «Заменить» подлежат просмотру в целях обнаружения возможных недочетов в работе алгоритма, его корректировки, либо ручной коррекции текста.